Kenyon Lab
Garrett T. Kenyon, Ph.D

Link to Curriculum Vitae
Please enjoy Dr. Kenyon's recent talk at Sandia's NICE 2015 Conference.
View other media and presentations on our media page
Featured PetaVision Research
Much of our research focuses on the use of sparse solvers to tackle hard problems in neuromorphic computing, such as depth reconstruction and image/action classification. The following examples are a brief showcase of some of the ongoing research in the PetaVision group.
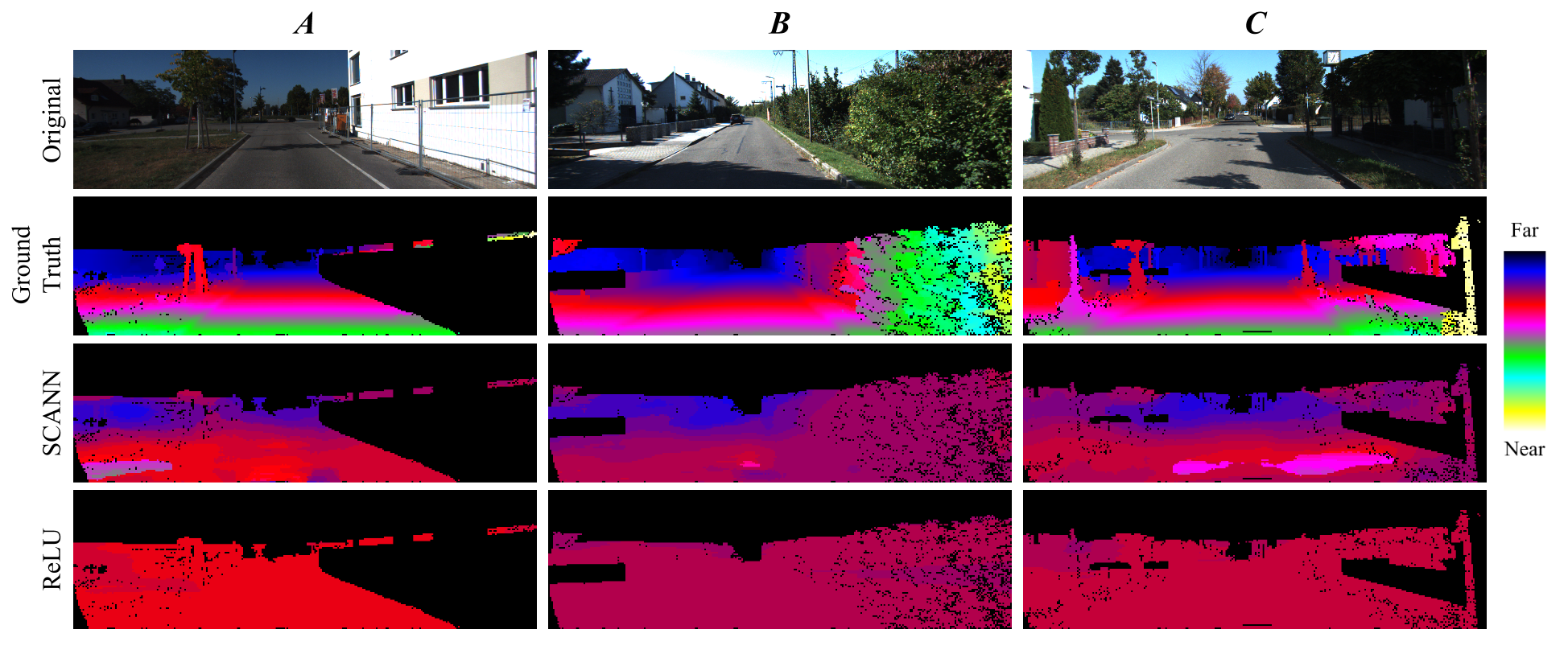
Depth-inference from two cameras Sheng Lunquist
Emergence of Depth Tuned Hidden Units Through Sparse Encoding of Binocular Images,"Sparse coding models applied to monocular images exhibit both linear and nonlinear characteristics, corresponding to the classical and nonclassical receptive field properties recorded from simple cells in the primary visual cortex. However, little work has been done to determine if sparse coding in the context of stereopsis exhibits a similar combination of linear and nonlinear properties. While a number of previous models have been used to learn disparityselective units, the relationship between disparity and depth is fundamentally nonlinear, since disparity can be produced by periodicity in the stimulus and does not uniquely determine depth. Here, we show that nonlinear depthselective hidden units emerge naturally from a encoding model trained entirely via unsupervised exposure to stereo video optimized for sparse encoding of stereo image frames. Unlike disparityselectivity, which is a robust property of many linear encoding models, we show that a sparse coding model is necessary for the emergence of depthselectivity, which largely disappears whe latent variables are replaced with feedforward convolution."



Multi-Intelligence Learning Max Theiler
In multi-INT analysis, as in most problems in machine learning, the needle of relevant data is buried in a haystack of noise. What makes it particularly difficult is that it calls for the reconciliation of data streams of wildly differing format, scope, consistency and granularity. The premise of mult-INT is that useful predictive higher-order correlations exist between these streams, but how can any automated system make sense of inputs as diverse as (for instance) twitter activity, video footage, and economic data?
Sparse coding presents an elegant mechanism for synthesis. By representing data streams as linear combinations of learned features, the varying scales and dimensions of diverse input streams can be collapsed into single-dimensional vectors of controllable size. So long as the dictionaries of features are well-tuned, the loss of precision in representing data this way is negligible. If different activation coefficients of features from different data streams rise and fall together, it implies a high-order relationship between those streams regardless of differences in their original format.
My work is to explore the possibility of adapting PetaVision to this purpose. The first challenge is training well-tuned dictionaries of features on non-visual data sets (currently, infrared satellite weather data and agricultural commodity prices). The second is to use sparse coding to find statistically significant relationships between these data sets and train a super-dictionary that encodes them, able to consolidate data from profoundly different streams. I aim to use example datasets to create a PetaVision proof-of-concept for a neural network along these lines.






Action Classification Wesley Chavez
Many sparse coding algorithms are restricted in the time domain, and don't make use of temporal dynamics in video, which can provide extra clues about the objects and actions being performed. We show that unsupervised learning with a modified, linked-dictionary LCA (locally competitive algorithm) in PetaVision can learn features with spatial, as well as temporal structure. Instead of one image/frame as the LCA's input, a sequence of consecutive video frames is presented, and each neuron in the sparse/hidden layer is then forced to approximate all frames at once, updating its linked (spatiotemporal) weights via Hebbian learning to encode not only spatial redundancies, but temporal redundancies of the input as well. Here is a .gif of spatiotemporal features learned (unsupervised) with a sliding window of four consecutive video frames as LCA's input in PetaVision:

We perform classification of objects in the DARPA NeoVision2 Tower dataset by using a linear single-layer perceptron (SLP) within PetaVision to learn the hyperplanes that separate the learned spatiotemporal features that correspond to the five different classes. (cyan = "person", green = "bicyclist", magenta = "bus", red = "car", blue = "truck"):